
giphy.com
Лингвист Борис Орехов о том, как установить авторство художественного текста, при чем здесь язык программирования и о загадке «Тихого Дона»
Но, например, личность Шекспира вызывает множество вопросов: кроме завещания, от него до нас не дошли никакие достоверно написанные им документы. Существует точка зрения, что произведения Шекспира принадлежат не Шаксперу из Страдфорда, а кому-то другому — кандидатов множество. Или, скажем, неясно, сочинил ли Гомер, кто бы он ни был, произведения, которые ему приписываются, — это не только знаменитые поэмы, но и так называемые «Гомеровские гимны»: он жил, по всей видимости, в те времена, когда в Греции вообще не было письменности.
Бывают также ситуации, когда источники есть, но они настолько противоречивы, что их можно трактовать в зависимости от собственного взгляда на предмет. Для сторонников версии, что Шолохов действительно написал «Тихий Дон», сохранившаяся рукопись произведения подтверждает его авторство, а противники такой версии считают, что это текст, написанный его рукой, но сочиненный другим человеком.
В случаях, когда нет убедительной доказательной базы в виде документов, люди прибегают к количественным методам анализа. Это область компьютерной лингвистики, которая задействует автоматическую обработку текста, чтобы выявить определенные закономерности в нем. Количественная атрибуция подразумевает, что автор так или иначе проявляет себя в произведении, оставляет своего рода «отпечаток пальца». Предполагается, что есть некоторый «авторский сигнал», который не зависит от того, в каком настроении был автор или на какую тему он писал. Это можно называть авторским стилем. Значит, этот «отпечаток пальца» можно установить какими-то объективными средствами контроля.
Появление количественной атрибуции
Идея количественной атрибуции появилась давно. Во второй половине XIX века возник новый подход к определению авторства картин. Он был сформулирован Джованни Морелли, который призвал пересмотреть подход к атрибуции в целом. Он утверждал, что нужно обращать внимание на детали, например на то, как нарисованы уши или пальцы. Скорее всего, художник не будет задумываться, как именно ему нарисовать ухо, потому что он привык его рисовать некоторым особенным образом. В XX веке Карло Гинзбург вернулся к идее Морелли и назвал ее «уликовой парадигмой».
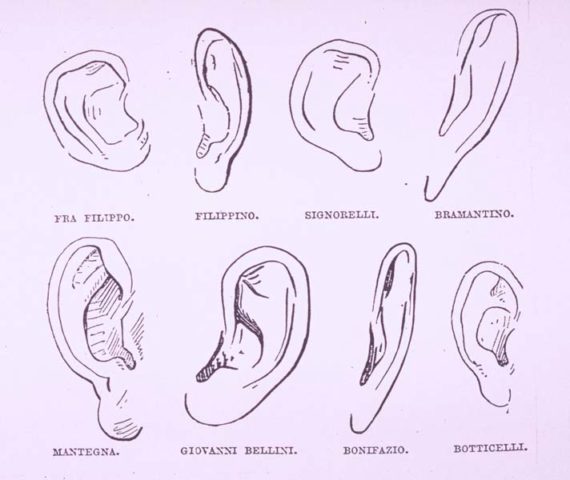
Томас Менденхолл примерно в то же время, что и Дж. Морелли, предположил, что таким неконтролируемым параметром может быть длина слова. Он посчитал длину слов в текстах Шекспира и пришел к выводу, что Френсис Бэкон, в сочинениях которого длина слов была приблизительно такой же, и есть Шекспир. Но, во-первых, Менденхолл ошибся при подсчетах, а во-вторых, сама по себе длина слов не является тем параметром, по которому можно определить авторство. Позднее за такой параметр принимали слова, лексемы, распределения падежных форм и так далее. Однако все это не дало убедительных для всех результатов.
Метод Дельта
Перелом случился в 2002 году. Джон Барроуз написал статью «Дельта: мера стилистической разницы», в которой сформулировал подход к задаче количественного установления авторства. Его метод получил название «Дельта».
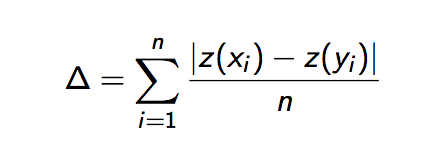
Технологии проверки авторства
На основе этого метода группой ученых была создана компьютерная библиотека для языка R — Stylo, которая стала считать эту самую дельту. Любой человек, даже не обладающий навыками программирования, может взять и проверить интересующий его текст, потому что у библиотеки есть графический интерфейс.
Создатели библиотеки добавили иерархическую кластеризацию (или, говоря проще, диаграмму в виде дерева). Наиболее близкие тексты оказываются на соседних ветках.
Джоан Роулинг решила попробовать себя в написании текстов, непохожих на «Гарри Поттера», и выпустила книгу под псевдонимом Роберт Гэлбрейт. «Дельта» однозначно указала, что тексты о Гарри Поттере стилистически совершенно соответствуют роману Гэлбрейта и не похожи ни на Толкина, ни на Льюиса, ни на кого-то другого. Уже после этого Джоан Роулинг публично признала свое авторство.
«Дельта» работает для многих языков: английский, арабский, китайский, немецкий, русский.
Однако есть примеры, когда она дает ненадежные результаты. Это происходит в том случае, если в исследовательском корпусе представлены разные жанры. Например, произведения Гончарова «Обрыв», «Обломов», «Обыкновенная история» сгруппированы вместе, а «Фрегат «Паллада» расположен ближе к Гоголю, потому как он написан в другом жанре: это серия путевых очерков.
Другие ошибки связаны с текстами слишком маленького объема. Если текст размером меньше 5000 слов, то результат будет ненадежный. Поэтому авторство «Отрывка из путешествия В*** И*** Т***» не удается установить достоверно. Объем этого текста всего лишь 1680 слов.
Загадка «Тихого Дона»
Но давайте вернемся к Шолохову. «Дельта» прекрасно отличает всех его современников: Ильфа и Петрова от Булгакова, Леонова от Горького и так далее. Некоторые утверждают, что первые две книги «Тихого Дона» написаны одним автором, а вторые две книги — другим.
По результатам анализа с помощью «Дельты» видно, что весь «Тихий Дон» написан одним автором и, видимо, тем же самым человеком, который написал «Донские рассказы». Тут надо уточнить: есть версия, что Шолохов не писал «Донских рассказов» и вообще ничего не писал. Но если мы верим в то, что Шолохов все-таки автор «Донских рассказов», тогда это тот же самый человек, который написал и «Тихий Дон».
Среди ученых, занимающихся количественной атрибуцией, существует версия, что автором «Тихого Дона» является советский писатель А. С. Серафимович. Идея, что «Тихий Дон» принадлежит не Шолохову, возникла почти сразу после публикации романа в журнале «Октябрь». Тогда же была создана специальная комиссия в рамках группы пролетарских писателей, которая должна была расследовать это. Этой комиссией руководил Серафимович, так что его идея об авторстве выглядит совершенно абсурдно: неужели ему нужно было расследовать кражу его собственного романа? И результаты «Дельты» показывают, что автором он, разумеется, не является: Шолохов по-прежнему наиболее вероятный кандидат на авторство «Тихого Дона».
Открытые вопросы атрибуции
С помощью «Дельты» можно определить не только автора, но и дату написания произведения. В течение жизни автора его стиль так или иначе меняется, и «Дельта» это видит. На диаграмме произведений Диккенса разных периодов показано, что романы, написанные в одно десятилетие, сгруппированы вместе.
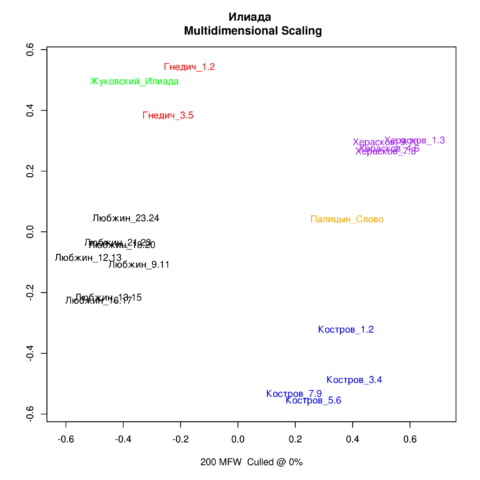
С помощью датировки можно также определять стилистические особенности перевода. Скажем, сравнивая перевод «Илиады» современного филолога А. И. Любжина и поэта XVIII века Е. И. Кострова, мы видим, что текст А. И. Любжина оказался в одном кластере с поэтами пушкинской эпохи, хотя А. И. Любжин как бы продолжает старый перевод, начиная там, где остановился Е. И. Костров. Тем не менее переводчик не повторяет манеру XVIII века, а говорит на более современном языке. Кроме текстов Кострова и Любжина к исследованию привлекались написанные тем же размером (александрийский стих) «Россияда» М. М. Хераскова, перевод «Слова о полку Игореве» А. Палицына, а также переводы «Илиады» Н. И. Гнедича и В. А. Жуковского, выполненные гекзаметром.
Чтобы признать новые методы компьютерной лингвистики, которые сейчас разрабатываются в большом количестве, надежными инструментами для определения авторства и решения других смежных задач, необходима их проверка многими исследователями, а для этого система должна быть удобной. Преимущество «Дельты», благодаря Stylo, в удобстве для пользователей.
Есть ситуации, когда мы не можем установить авторство в принципе. Например, мы вряд ли узнаем, кто написал «Слово о полку Игореве». Это касается вообще большинства древних текстов. Еще одно значимое произведение — диалоги Платона. Философы придерживаются мнения, что Платон в своих ранних диалогах излагал не собственные идеи, а транслировал реальные диалоги своего учителя Сократа. С какого-то момента Платон начинает использовать эту форму уже для передачи нового содержания, продуцирует свою собственную философию, которая отличается от системы Сократа. Поскольку нет никаких документов, которые бы позволили провести эту разграничительную линию, логично появление попыток количественного решения этой проблемы. Этим занимался Винцента Лютославский в XIX веке, который, вероятно, и придумал само слово «стилометрия», которым мы обозначаем количественное исследование стилистики текста.
Очевидно, что одной «Дельты» не всегда достаточно для убедительных результатов определения авторства: она не может работать с короткими или разножанровыми текстами. Нужные другие методы, которые позволят это делать. Новые инструменты нужны, но не как замена «Дельты», а как дополнение в тех сферах, в которых она не справляется.
Полезные ссылки
1. Для проверки текстов с помощью «Дельты» сначала нужно установить R, это свободный и бесплатный интерпретатор языка R. Установщик для Windows, Mac и Linux. Если у вас уже стоит R или даже R Studio, то ничего дополнительно не нужно.
2. Попробовать открыть R — его значок выглядит вот так:
3. Напечатать в командной строке install.packages («stylo») — это установка пакета для стилеметрии. Нажать Enter. Он предложит выбрать зеркало, берите первое (Cloud).
4. После этого опять попробовать вызвать установленный пакет командой library (stylo). Нажать Enter. Он в ответ должен сказать, какая версия stylo. Что-то вроде ### stylo version: 0.6.5 ###
5. Наконец, попробовать запустить графический интерфейс stylo, вызвав функцию stylo (). Нажать Enter. Должно появиться такое окно:
6. Если вы используете MacOS и на экране появилась ошибка с упоминанием XQuartz — надо пойти на этот сайт, поставить XQuartz, перезагрузиться и снова попробовать пункты 2—5.
7. Создайте на компьютере папку, которая называется corpus (это важно, называться она должна именно так).
8. Укажите stylo, где находится папка с вашим корпусом.
9. В открывшемся меню в первой вкладке (Input & language) ставим язык Other и галочку UTF-8.
10. Если не трогать остальные настройки, то после нажатия «OK» тексты из папки corpus кластеризуются по своей стилеметрической близости.
11. Дальше можно изучить документацию и howto и начать работать самостоятельно.
Источник: ПостНаука